
How to Using OCR to Read Specific Pages from a PDF in UiPath

Introduction:
In automation scenarios, reading PDF documents using OCR (Optical Character Recognition) is a common task. However, sometimes you may need to extract text from specific pages of a PDF rather than processing the entire document. In UiPath, while it is possible to read a PDF with OCR, extracting content from specific pages, especially using OCR, can be tricky.
This article explains a method to read specific pages from a PDF using OCR in UiPath and offers solutions to overcome common challenges.
Common Issues:
- OCR Accuracy: OCR may struggle with certain types of documents, such as scanned images or PDFs with complex layouts.
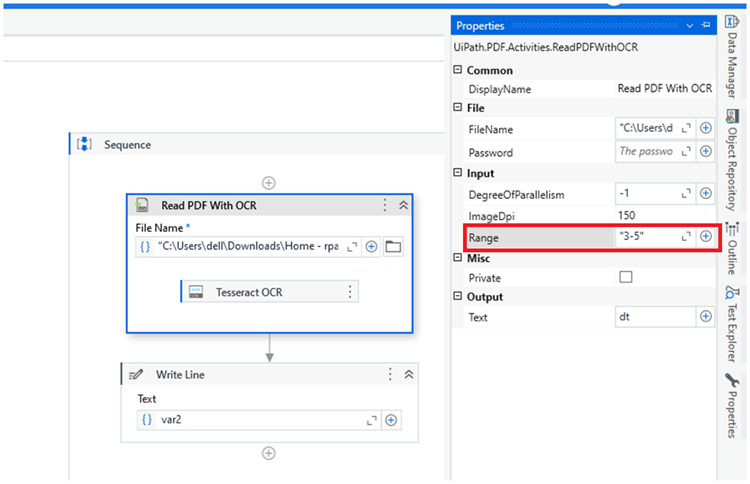
- Range Failures: Directly specifying a page range might not work if the OCR engine fails to handle multiple pages at once.
- File Size and Memory Issues: Large PDF files can cause memory overload when processed in their entirety with OCR, leading to workflow failures.
Solution:
Read the Extracted PDF with OCR:
- Now, use the Read PDF with OCR activity to process the extracted single-page PDF. Select the OCR engine you prefer (e.g., Tesseract, Google Cloud OCR, Microsoft OCR).
- Configure the OCR settings such as language, scale, and resolution for better accuracy.
Conclusion :
When OCR fails to read specific pages from a PDF directly in UiPath, splitting the document and processing individual pages provides a practical workaround. By isolating pages, you can mitigate issues with range processing and improve OCR accuracy. Additionally, UiPath offers multiple OCR engines and advanced document understanding models, which provide flexibility based on your use case. This method ensures that your automation workflow is robust and can handle various PDF structures effectively.
Also Read – Fuzzy Vs Strict Selectors: Improving The UI Experience For Robust Automation






